地平线5最高等级是多少
翁玲13394464871…… QQ飞车最高级别为150级,称号“车神”. 0~10级新手11~20级车手21~30级快车手31~40级飞车手41~50级驾御者51~60级竞速者61~70级超越者71~80级领先者81~90级羚之先锋91~100级猎豹先锋101~105级雄鹰先锋106~110级飞龙先锋111~115级风速骑士116~120级火速骑士121~125级闪电骑士126~130级雷霆骑士131~135级车圣136~140级车霸141~145级车王146~150级车神
@戎牲2565:斗地主最高的级别是多少? -
翁玲13394464871…… 级别 等级 等级名 分数 1 短工 100 以下 2 长工 100 3 佃户 200 4 贫农 400 5 渔夫 600 6 猎人 1000 7 中农 2000 8 富农 4000 9 掌柜 6000 10 商人 10000 11 衙役 20000 12 小财主 50000 13 大财主 100000 14 小地主 200000 15 大地主 500000 16 知县 1000000 17 通判 2000000 18 知府 5000000 19 总督 10000000 20 巡抚 20000000 21 丞相 50000000 22 帝王 100000000
@戎牲2565:QQ飞车中玩家最高等级是多少 -
翁玲13394464871…… 满级150级 0~10级 新手 11~20级 车手 21~30级 快车手 31~40级 飞车手 41~50级 驾御者 51~60级 竞速者 61~70级 超越者 71~80级 领先者 81~90级 羚之先锋 91~100级 猎豹先锋 101~105级 雄鹰先锋 106~110级 飞龙先锋 111~115级 风速骑士 116~120级 火速骑士 121~125级 闪电骑士 126~130级 雷霆骑士 131~135级 车圣 136~140级 车霸 141~145级 车王 146~150级 车神
@戎牲2565:防爆手拉葫芦防爆等级是多少?防爆手拉葫芦一般能适应什么场合使用? -
翁玲13394464871…… 防爆手拉葫芦防爆等级是防爆等级是dⅡAT2到dⅡAT4.d代表隔爆型.II代表II类防爆,即厂用防爆.C代表可用于C级防爆区域,也就是可用于最危险的区域.T4代表温度组别 ,从T1-T6,达到T6的是最高的.防爆手拉葫芦可广泛应用于石油、...
@戎牲2565:超Q黄金等级最高多少级? -
翁玲13394464871…… 最高6级哦,呵呵...采纳下哦!
@戎牲2565:绿钻最高等级是多少???我现在6级 -
翁玲13394464871…… 最高的是7级· Lv1 32M Lv2 64M Lv3 128M Lv4 256M Lv5 512M Lv6 1024M Lv7 1024M 等级高上传本地歌曲到空间容量大些.
@戎牲2565:热血江湖现在最高是多少级,要达到这个级别最快需要多长时间? -
翁玲13394464871…… 目前等级最高为112级,现在最高也就升到115吧,都没有高级怪,升不了的,等级相差10级就没经验啊!!不过,马上有两个新地图出来了,估计会高一些吧!!
@戎牲2565:问问的最高级别是多少?目前最高的是? -
翁玲13394464871…… 最高20级720000分以上,日前最高17级
@戎牲2565:《植物大战僵尸2》对战模式的基地最高等级是多少? -
翁玲13394464871…… 植物大战僵尸2对战模式的基地最高等级是20级.基地、阳光、人口等级最高20级上限6000奖章120W星币、5500阳光、100人口. 一.《植物大战僵尸2:奇妙时空之旅》是由宝开游戏公司联合美国艺电公司开发的一款益智策略类塔防御战游戏...
@戎牲2565:龙之谷的最高等级是多少啊? -
翁玲13394464871…… 现在顶级是50.谢谢采纳

3月28日,智东西公开课组织的「自动驾驶新青年讲座」第16讲顺利完结。在这一讲中,地平线工具链核心开发者杨志刚以《基于征程5芯片的Transformer量化部署实践与经验》为主题进行了直播讲解。
杨志刚首先介绍了Transformer发展趋势及在嵌入式智能芯片上部署的问题,之后重点讲解了以征程5为例的嵌入式智能芯片的算法开发流程,并对以SwinT为例的量化精度提升和部署性能优化做了详细解读,最后分析了如何在征程5上既快又好地部署Transformer模型。
本次讲座分为主讲和Q&A两个环节,以下则是主讲回顾:
大家好,我叫杨志刚,在地平线主要负责天工开物工具链的开发,比如征程2、征程3、征程5上的系列量化工具和算法工具的一些开发和验证工作。因此和我们公司内部的算法团队、编译器团队都有比较深入的接触。
今天我分享的主题是《基于征程5芯片的Transformer量化部署实践与经验》,然后也会从量化和部署两个方面分析如何让Swin-Transformer在征程5上跑得既快又好。
以下是本次讲座的主要内容,大概分为4个部分:
1、Transformer发展趋势及在嵌入式智能芯片上部署的问题
2、以征程5为例的嵌入式智能芯片的算法开发流程
3、以SwinT为例的量化精度提升和部署性能优化
4、如何在征程5上既快又好地部署Transformer模型
01
Transformer发展趋势
及在嵌入式智能芯片上部署的问题
第一部分是Transformer的发展趋势以及它在嵌入式智能芯片上的部署问题。最近,我估计大家都对Transformer势不可挡的趋势有所了解,它确实已经在NLP领域甚至在图像领域都起到了不可替代的作用。比如从2017年Transformer被提出来以后,因为它超强的序列建模和全局建模的能力,所以Transformer模型结构其实已经在整个智能模型结构里有着越来越重要的地位。
一方面,它引领了一个大模型的潮流(当然这个潮流主要是指NLP领域),比如最近比较火的BERT、GPT等这样以Transformer为基础的模型其实在NLP领域已经起到了一些根本性的变革,还有像GPT这种模型的参数量从亿级别到千亿级别,我们能看到 Transformer的容量还有模型发展的趋势都朝着越来越大的方向发展。当然越来越大的前提是我们可以通过更大的模型去获取更高的精度,所以这个量级基本上已经从亿级别到了千亿级别、万亿级别。
另外一方面,Transformer不仅在NLP领域引领了大模型的潮流,而且在图像领域也有着越来越重要的地位。我这里截的图(如图一所示)主要是它在Backbone也就是分类ImageNet上面的一个趋势图,可以看到随着它的计算量、参数量越来越大,它的正确率也会越来越高。
事实上它在常见的基础任务中(比如说常见的检测、分割、跟踪等这样的任务)制作刷榜的时候,可以看到前几名里基本上已经遍地都是Transformer的影子了。所以比如常见的以Swin-Transformer为例的encoder,以DETR为例的decoder,还有时序、BEV等这种用Transformer做特征融合的,不管在图像领域的哪一个阶段,我们都可以把Transformer的特性和CNN结合,甚至替代CNN的模型结构。无论是替代CNN还是和CNN结合,这两个发展方向都已经成为视觉领域的常用做法,所以整体上来说Transformer在现在的图像领域里已经是无法绕开的模型结构了。
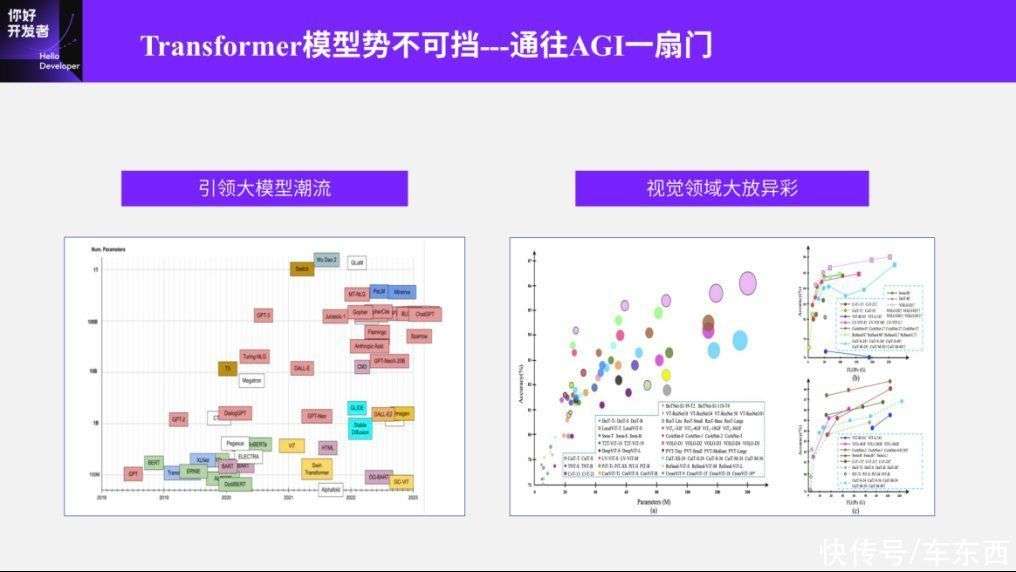
其实我在标题里面新加了一句话“通向通用人工智能的一扇门”,当然这个话我不敢说,我也是在一些别的信息上看到的。现在基本上认为,在我们做特征提取的阶段中,Transformer是通用人工智能的一种组件,所以也被称为一扇门,不过这个不是我们今天要分享的重点。
Transformer确实在模型结构上起着越来越重要的作用,但是另一方面,它在嵌入式端部署的问题也会受到越来越多的重视。具体来说,Transformer越来越大和嵌入式智能芯片部署这两个方向的出发点是有区别的,比如说Transformer模型在发展上是越做越大、越做越宽,但是嵌入式智能芯片因为受到成本、功耗等方面的限制,导致它在算力、带宽等很多功能方面受限,这就导致当前的嵌入式智能芯片不管是部署稍微大一点的还是小一点的Transformer模型,都会有一些吃力。

这里我讲三个主要的例子。第一个因为嵌入式智能芯片受到成本和功耗的限制,所以它的算力、带宽、内存等方面都会受到一定的限制,这就直接导致像Transformer这样的大模型的部署会受到限制。因为如果用一个大模型去部署一个小算力的平台,就算不是Transformer哪怕只是普通的CNN,性能显而易见的可能会极差,更何况是Transformer这样的大模型在小算力平台上的部署很明显会有一些缺陷。
第二个特征是目前市面上比较流行的嵌入式智能芯片通常都会以低精度的方式来处理部署的模型。当然低精度之外也会少量的去支持一定精度的浮点,这个原因和算力、带宽受限是一样的,主要还是从成本、功耗等这方面的情况考虑的,所以这就直接导致了如果想要在嵌入式智能芯片上部署的话,那么这个模型可能要经过一些量化,但同时量化不能有一定的精度损失。否则如果精度损失比较大的话,这个部署就是没有意义的。
第三点是芯片的发展其实是滞后于算法的。关于这一点,在我们公司罗老师之前的分享当中(地平线罗恒博士:如何打造一颗好的自动驾驶AI芯片)有比较详细的描述,大家如果有兴趣可以去看一下。简单来说,就是芯片从设计到正式量产需要经过一个漫长的过程,这个过程可能是2-4年。因此现在市面上流行的嵌入式智能芯片基本上是源自于1-2年甚至更长时间之前的设计,而那时候设计的嵌入式智能芯片很大概率没有考虑Transformer的情况,因为那时候可能大部分市面上流行的还是以CNN为主的模型,所以这样就会造成现在大部分嵌入式智能芯片对CNN的部署非常友好,但是对Transformer的部署存在一定的gap。今天我们就要讨论这个gap到底来自哪里。
下面我们详细拆解一下刚刚讲到的问题:Transformer部署过程中会遇到哪些问题?

第一个是量化问题,其实Transformer的量化问题现在我们能在很多社区的论文或者一些博客当中看到。首先,它为什么要经过量化?我刚刚简单讲了一下,它是从成本、功耗等方面考虑的。如果用int8或者低比特的量化部署,它的好处是显而易见的,比如可以降低功耗、提高计算速度、减少内存和存储的占用。这里有个数据对比,Transformer部署的时候其实会有一些常见的问题,如果熟悉量化训练的同学应该比较清楚,Transformer模型当中有大量的非线性函数,比如说像GeLU、LayerNorm这样的东西。所以它激活值的输出和高斯分布会有比较大的差异,这就直接导致了很大一部分之前在CNN中最常用的对称量化的方法,可能会出现很明显的精度问题。
如果要解决Transformer的量化精度问题,社区有很多常见的经验。我这里举两个例子,比如用非对称量化等方法去处理分布不均衡或高斯分布差异较大的情况,还有一些情况可能会直接在硬件上使用浮点的SoftMax或LayerNorm,这种情况肯定是可以解决量化问题的,但实际上我们需要和硬件结合,而硬件上到底能不能支持浮点或者能不能支持非对称性量化是我们需要考虑的另一个问题。我们今天要讲的征程5的平台,它就是一个纯int8的嵌入式智能平台,如果要在一个纯int8的嵌入式智能平台上去部署一个浮点的SoftMax或者LayerNorm显然是不合理的。甚至有一些情况就算它是纯int8的,可能也不支持非对称量化,所以我们如果要解决Transformer量化不友好的问题,还需要结合硬件的特点来考虑。
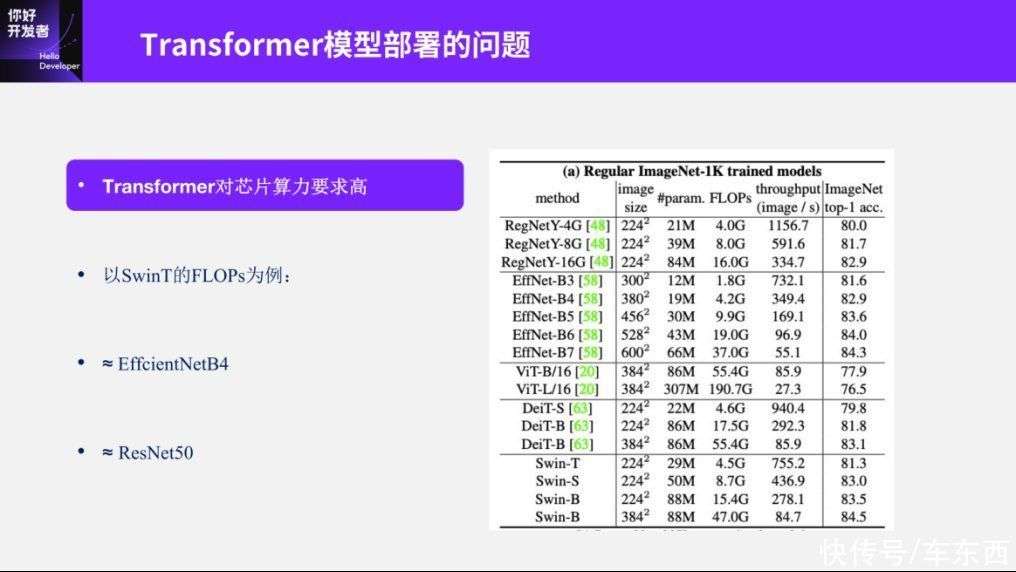
Transformer模型部署的第二个问题是Transformer对算力的要求比较高。开始也讲到,Transformer是近年来最受关注的神经网络模型,而Transformer在机器视觉领域最重要也是最彻底的应用就是Swin Transformer,这个工作也得到了机器视觉领域最高的奖项,马尔奖。这里我们以Swin-Transformer为例。我们考虑Swin-Transformer这个最小的模型,它的计算量大概是4.5G左右。
说4.5G可能很多人没有直观概念,我做了两个简单的对比,这就约等于我们常用模型里的EffcientNetB4和ResNet50。说到ResNet50,很多人就有概念了,如果我们用ResNet50的水平去做部署的话,其实市面上很多算力稍微低一点的嵌入式智能芯片部署就会有点吃力了。如果有人知道地平线的历史,比如地平线的上一代芯片跑ResNet50是可以跑的,但它的效率不是很高,而且这还是CNN的部署效率,如果在Transformer上效率会进一步降低。这样考虑的话,整个SwinT部署的前提条件就是芯片的算力达到一定的要求。
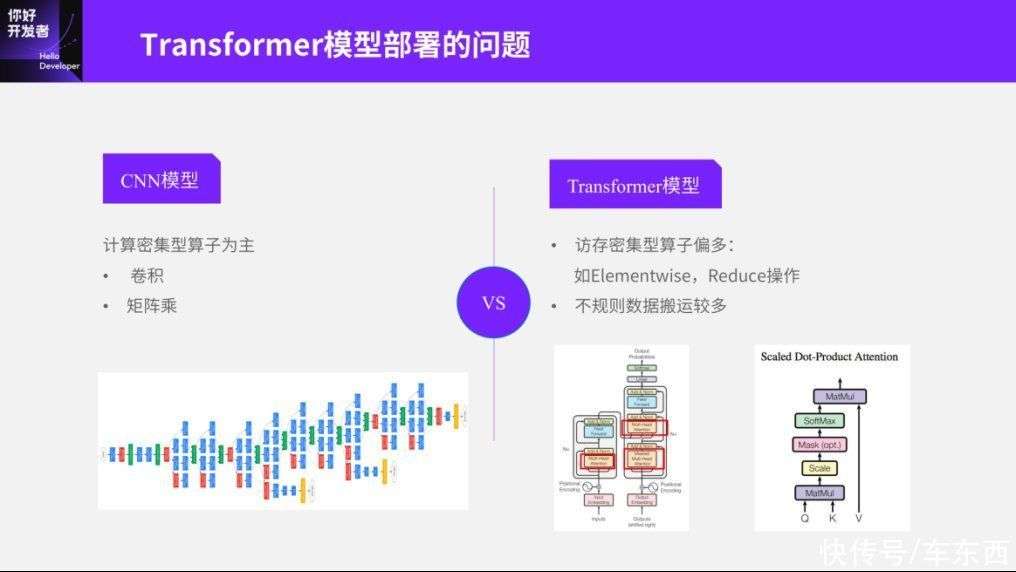
除了刚才提到的SwinT的基础还有量化问题之外,还有一个比较重要的问题就是我们一直在讲的Transformer和CNN模型到底有哪些区别?为什么说我的芯片可以部署ResNet50,但是没法部署Transformer呢?其实这就是CNN模型和Transformer模型之间一个比较重要的区别。如果我们比较熟悉CNN模型,就会知道CNN基本上从头到尾只有一个卷积,或者有少量的非卷积算子,如RoiAlign。所以整个CNN模型实际上是以卷积和矩阵乘为主的。换句话说,这类算子的特征是以计算密集型算子为主。我们早期的智能芯片为什么并发能力强,因为智能芯片设计之初就是以这样的CNN模型为出发点的,它的重点是利用并发去解决计算密集型的问题。
但在Transformer里情况是不一样的,Transformer里除了我们刚刚说到的卷积和矩阵乘以外,还有大量像Elementwise、Reduce这样的访存密集型算子。访存密集型算子和计算密集型会有明显的区别,会要求我的访存带宽或者访存本身的存储容量比较高,同时不规则的数据搬运比较多,不像CNN中,一个4d-tensor可以从头到尾,而且我的4d-tensor的规则可能非常明显:W/H维度做下载样,C维度做特征变长,这种4d-tensor的特征对整个嵌入式智能平台是非常友好的。
但Transformer中不规则的数据搬运会明显多很多,比如像Swin-Transformer,我们做window partition和window reverse时会有很多Reshape和Transpose的操作,这种操作带来的问题是效率会进一步降低。事实上这个问题是整个Transformer或者说整个芯片行业都会遇到的一个问题,不仅是嵌入式智能芯片会有这样的问题,训练芯片也会有类似的问题。
我记得早几年前英伟达在测试上做过一个OPS的简单统计,这个细节就不说了,大体上的结论是纯粹计算型的算子,比如卷积和矩阵乘这样的算子在计算量上占比大概99.8%,但实际上它在英伟达芯片(就训练芯片上而言)的执行时间只有60%。换句话说,训练芯片本身有大量的占比很低的非计算型算子,但这些算子却花费了40%的时间。这个问题在Transformer部署嵌入式智能芯片时,会被很大程度的放大。常见的嵌入式智能芯片可能会有大量的时间浪费在访存算子和不规则数据搬运上面。
总结一下第一部分,就是嵌入式智能芯片由于受到成本、功耗等方面的限制,设计思路和实际上需要部署的Transformer模型之间有较大的区别。
02
以征程5为例的
嵌入式智能芯片的算法开发流程

第二部分重点讲一下嵌入式智能芯片的开发流程,这里虽然是以征程5为例,但实际上我们通过目前的调研或者就目前大部分嵌入式智能芯片总体上看,开发流程基本上是一致的,所以换句话说,大家要解决的问题基本上类似。
首先简单讲一下征程5的基本情况,这在之前的系列课里有比较充分的描述,是讲征程5是怎么设计出来的,然后针对智驾平台有怎样的创新或者怎样的用处,我就不多讲了,这里我主要讲这几个基本情况是如何符合Transformer部署的前提条件的。然后这个也和我们刚才说的常见的嵌入式智能芯片部署的缺陷对应上。
第一点是大算力计算平台,首先我们得有一个大算力计算平台作为前提,才有可能去部署Transformer系列模型。如果是小算力的话,刚刚也讲了,比如上一代征程3想部署Transformer可能就比较困难。
第二个重点是丰富的算子支持。我们在刚才Transformer的结构图中也能看到这点为什么比较重要,CNN模型的主体是以卷积为主,配合少量其他算子,如RoiAlign等。但Transformer中其实有很多很杂的算子,比如说像LayerNorm、SoftMax,还有Reshape、Transpose等,所以说智能芯片部署Swin-Transformer或者其他Transformer的前提条件除了大算力之外,还需要非常丰富的算子知识。
另外是最强的计算性能,我觉得在我们Transformer的部署中其实没有太多的参考价值,因为它是以CNN为基础的模型进行统计的,也就是以计算密集型的模型统计的,但Transformer的能力跟这个还是有比较明显的差距。
最后一点是超低功耗,这点也需要多讲,因为它本身也是征程5的亮点之一。地平线的征程5和天工开物工具链,其实已经积累了一套比较完善的软件工具,这套软件工具从用户训练的浮点模型开始,然后做量化、训练、编译、部署、优化等,最终部署到嵌入式端。以量化为例,基本上整个芯片工具链会提供PTQ的后量化和QAT的量化训练这两种量化方式。在优化编译阶段,可以提供Checker、Calibrator和分析、仿真等工具,最终可以保证用户的模型经过量化、优化后,能部署到嵌入式端。这里需要说一下早期的天工开物整个工具链的积累其实是基于CNN模型的,后面我也会讲为什么基于CNN模型积累下的整个芯片工具链在处理Transformer模型时,不管是量化还是优化部署方面都有一定缺陷。
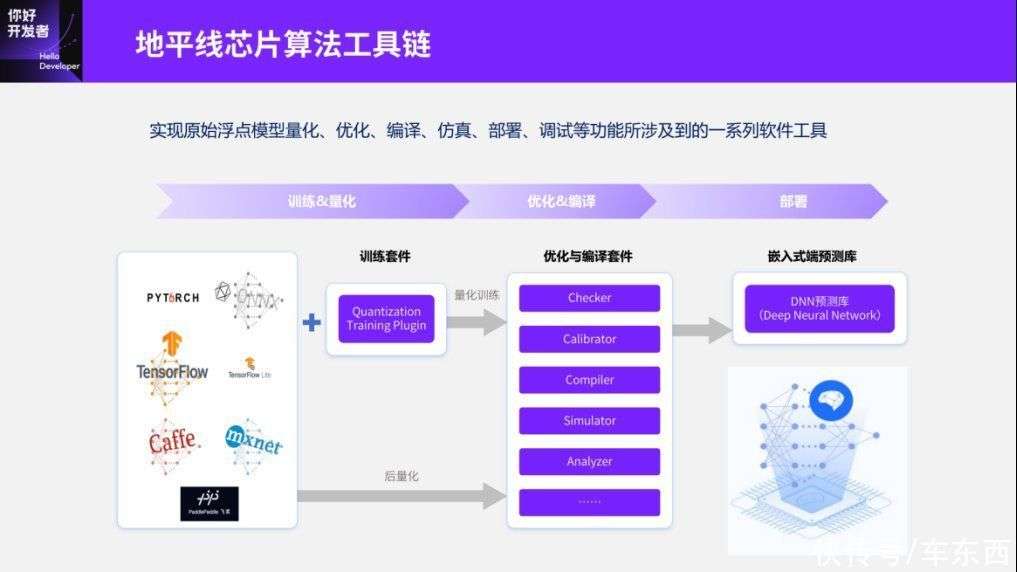
下面是如何利用整个天工开物工具链帮助用户把浮点模型快速部署到嵌入式芯片上。这就是我一开始讲的,各家的芯片工具链、各家的嵌入式智能芯片的部署流程已经趋于相同了,整体上都是从算法迁移代价足够小的角度考虑,所以基本上已经是一个标准流程了。然后我们来看一下这个流程,从浮点训练开始,经过PTQ后量化的校准,如果后量化的精度满足要求我们就可以直接编译优化、最终部署;如果不满足要求可以反过来去做量化感知训练,量化感知训练的目的是使精度达到要求,并最终去做模型定义。那么如果我们要处理这种Transformer部署优化的流程,要处理的两个重点就是量化调优和编译优化,主要是利用量化公式去提升量化精度。第二个是在编译过程中,用手动或自动的方式去获取更好的部署性能。
天工开物工具链首次把Swin-Transformer部署在征程5上,其实没有遇到太多困难,当然这个前提我刚刚已经讲了,首先它有大算力,然后丰富的算子知识,这两点我们在征程5上的部署过程比较简单。这里简单讲一下支持哪些算子,其实了解Swin-Transformer的人应该都了解,比如说有Reshape、roll、LayerNorm、matmul等。这里为什么需要算子完全支持?我们一开始做这个事情的时候发现 ONNX opset上面没有完全支持roll,所以当时测Swin-Transformer在其他品牌上的结果时,还需要单独处理roll的情况。最近,我们发现opset上已经支持roll了,但另一个方面说明一些嵌入式智能芯片的平台不管是由于使用的工具还是最后部署的芯片的限制,想做到算子完全支持有一定的门槛。
第二点就是量化精度,总体上来看,量化精度经过QAT之后,大体上量化精度损失了4个点,这里需要说明一下就是量化损失4个点可能看起来不是那么糟糕,但是我们在之前的工具链当中已经沉淀了一系列的精度debug工具和提升方法。不过它的局限性可能是以CNN为主的模型,而CNN模型我们通常可以快速定位出它的量化损失来自哪里,但是当有一些经验映射到Transformer上时没那么通用。因此在CNN经验积累的基础上,我们才得到了损失4个点的结果。
最后一个是首次部署的FPS小于1,可以说性能极低,基本上不可以用。这里我们参考一下征程5上其他一些CNN的模型数据,比如ResNet50大概会超过600FPS,EffcientNet LiteB4大概会超过1000FPS。实际上如果是地平线自己设计的高效模型这个数字还会更大。但我们要解决的不是CNN的问题,而是CNN和Transformer之间的gap没有解决的问题,所以Transformer部署的瓶颈显然不能直接使用CNN的经验。

第二部分总结来说就是在征程5上沉淀出的天工开物工具链的标准流程,虽然可以很好的解决CNN的问题,但并不能完整的解决Transformer量化部署的问题。所以接下来以Swin-Transformer为例,讲解如何结合征程5平台做量化精度提升和部署性能优化。
03
以SwinT为例的
量化精度提升和部署性能优化

首先第一点是我们说在CNN上积累了一套基础配置或者说标准流程,那这个标准流程到底是指什么?这就需要讲一下天工开物中量化训练的基础配置,不过这里不需要讲PTQ的后量化,因为PTQ后量化除了方法的选择上有一些空间外,训练的空间不是很大,所以我们重点讲一下量化训练的技术配置。在之前的演示中,我们把PTQ跟QAT分开看,即要么执行PTQ的后量化,要么使用 QAT的量化训练。
但事实上我们在一些经验中发现,如果我们使用PTQ的后量化参数去给QAT做初始化时,就可以给QAT的初始状态提供一个更高的起点,这也可以保证QAT的量化训练收敛的更快。所以目前的量化训练,不管是CNN还是Transformer都是PTQ+QAT这样的流程,这基本上已经变成一种标准化操作了。另外,常见的一些CNN配置,比如全局使用int8,只在输出阶段使用int32。还有像QAT过程中有一些超参的配置,比如说Lr我们一般是10⁻³、10⁻⁴,Epoch大概是浮点的10%-20%,这个我不需要多讲,如果有量化训练经验的同学,可能对这个比较了解。
然后讲一下量化精度如何进行调优,其实我们非常不建议在PTQ尝试更多的方法或者盲目的调整QAT的参数,而是使用更加合理的可以快速分析出是什么导致量化损失误差的方法。比如说我们内部一般会把量化损失的误差从工具角度分为三个部分,比如说是算子误差、模型误差还是精度误差?可能大家都比较了解单纯的一个算子经过量化标准之后的误差是怎样的。模型误差是指,比如在相同的输入情况下,我们去识别出有一些FeatureMap比较大或者说分布非常不均衡,这种FeatureMap其实对量化会非常不友好。还有包括模型本身的误差,可能还包括weight这些参数,比如训练下来如果也有一些比较大的weight,其实这样对量化也是不友好的。另外就是精度误差,我们一般使用分布量化的方式,看模型中哪一个模块对最终整个数据集+模型的误差最大,这就是精度误差。
下面这两个图是我们量化损失分析工具提供的一个可视化结果,我们可以从非常直观的角度看到算子或模型本身的误差,还有一些weight分布的误差。第二个问题是如果我们识别出误差比较大的计算应该怎么处理?简单的方法是我一开始讲的浮点操作,但如果芯片不支持浮点操作的话,那就应该寻求其他更高精度的表达,比如征程5上是支持一些少量int16的,但int16可能不是原生支持,因为我们可以通过简单的操作用一些int8拼凑出来一个int16。所以如果我们想对一些算子做更高精度的表达时,优先采取的就是int16。
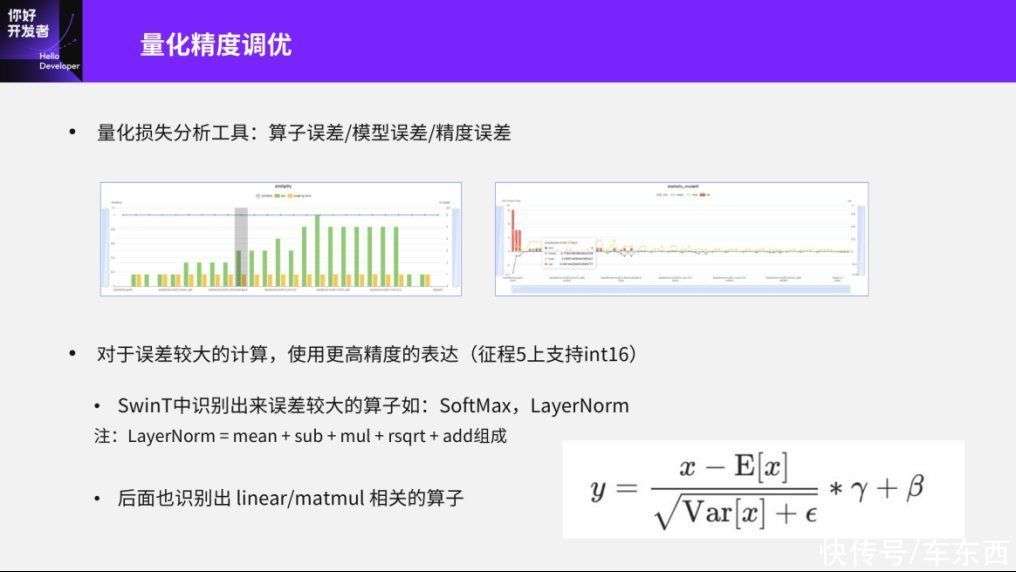
另一方面,如果我们要在下一代芯片或者一个对Transformer部署友好的嵌入式智能芯片上更好的部署Transformer,可能有些算子用浮点会有更好的结果。我们这里面主要使用int16的方法来解决量化误差的问题。以LayerNorm为例,在量化过程中我们其实是将LayerNorm拆成具体的算子,比如加减乘除、开方、add等操作,然后所有的中间结果除了输入输出之外,像mean、加减乘除等全部采用int16的方法,这样可以使LayerNorm或SoftMax这两个误差较大的算子获得更高的精度表达。
可能很多人会说SoftMax和LayerNorm不需要我们这样做,也能识别出量化损失误差,因为我一开始就讲了,他们在输出分布范围方面就明显不符合高斯分布,或者说像之前GeLU的情况。但其实我们在后来的一些检测实验中得出一些结论,一些特殊的linear或者matmul,如果有针对性地使用int16,比如在linear输入的情况下使用int16,在有些matmul输出的情况下使用int16,其实可以得到更好的精度结果。
第二部分是量化精度解决之后,编译部署优化的问题。这里我放出一些基本的统计数据,这是编译器或Swin-Transformer首次在征程5上部署时的基本情况。第一个是张量Tensor和向量Vector的计算比例大概是218:1,所谓的张量计算、张量Tensor实际上是指矩阵乘、卷积等操作,而向量Vector的计算,其实是指Normalization等操作,它的计算比大概是218:1。
直观的看这个数字可能看不出来,但我们可以对比CNN的情况,如果绝大部分模型都是张量Tensor的计算结果,那这个比例其实可以接近无穷大,而在无穷大的情况下,专门针对并发设计的嵌入式智能计算平台其实可以更好的发挥它的并行效率。而这样一个比例,可能就需要芯片本身有更多的时间去处理向量Vector。另一方面,Reshape和Transpose的数据搬运算子占比比较高,这个可能也和一些历史遗留问题有关,比如在之前的CNN中其实都没有遇到这类算子本身的实践方式,所以它的功能或者性能优化等做的不是特别完善,这也是导致Swin-Transformer部署效率极低的原因之一。
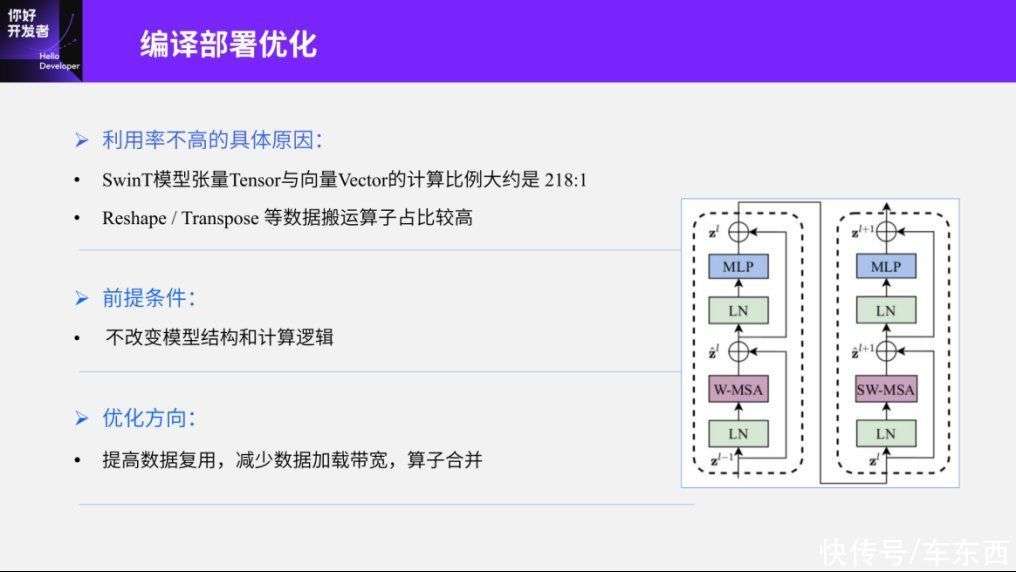
另外讲一下我们整个编译器部署的优化,总的前提是我们不应该改变整个模型结构和计算逻辑,这样不管我们怎么优化,用户都不需要重新训练浮点模型和量化模型。如果这个成本降下来的话,不管用户怎么改变,我们只要等价替换就可以了。优化方向是编译器优化常见的思路,比如提高数据复用,减少数据加载的带宽,然后还有一些算子合并等。
下面重点讲一下具体有哪些操作,我们大概总结了5个优化方向,有一些需要算法侧感知,有一些由编译器侧直接完成不需要算法感知。在说明过程中我们也会一一提到这些。
第一个是算子的映射优化,简单来说,是编译器端去丰富算子实现的功能,这样对于他们来说,每个计算单元、计算组件可以覆盖更多的功能。这样对部署而言,单独的算子就可以完成多个功能,从而在算子内部增加并行的机会。比如以matmul为例,一般来说,我们做QAT这种自注意力时会用matmul,然后在matmul前后会配合一些Transpose来使用。在这种情况下,从编译器的角度来说,matmul可以把Transpose吃进去,这样就是Transpose+matmul,即可以通过一个matmul算子来完成并且提高了算子并行的机会。
另一个LayerNorm的例子中也是类似的,LayerNorm前后如果有view或者Transpose操作的话,可以把前后维度变化融合到上层内部,这样我们就可以通过一个自定义的算子支持丰富的维度,那么view操作可以达到前后加Transpose的效果。这样的话,这个接口的修改需要用户感知,比如使用天工开物工具链对外释放的包中提供的算子接口,才可以使用这样的功能。当然这里其实是单纯为了优化性能而做的,使用原来的接口支持或部署是没有障碍的。
第二个部分是算子融合。算子融合其实比较简单,整个征程5的数据排布是一种多维的表示,而Reshape和Transpose操作是对CPU和GPU的数字行为作描述,所以如果我想在征程5上做多次的、连续的、线性的重排布,理论上征程5可以一次性统一排布。
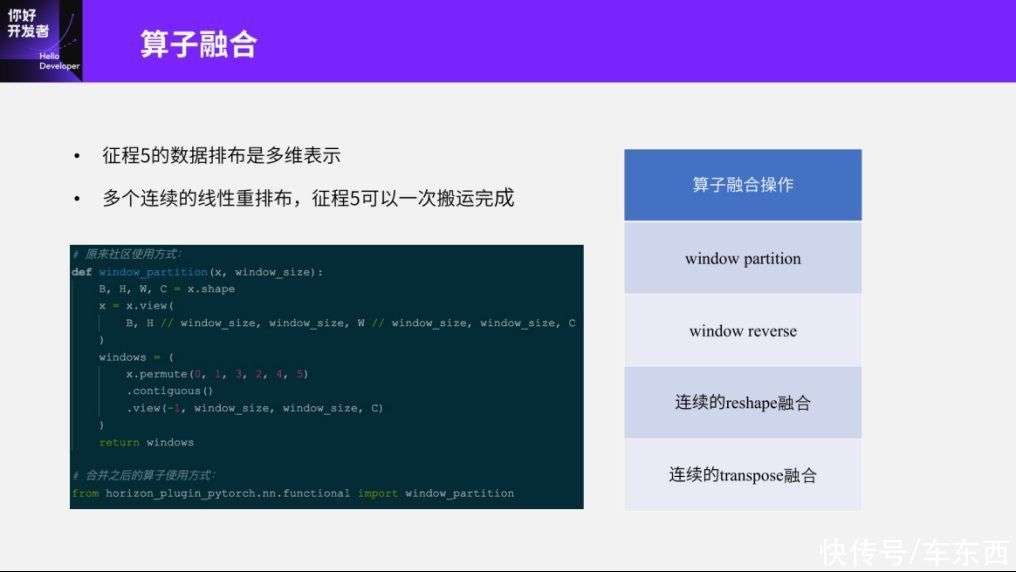
这里比较明显的是window partition和window reverse这两个算子,这两个算子内部主要是一些Reshape、view、permute等操作,简单来说就是不规则的数据搬运。对于征程5来说,我们优化的方向就是把这些东西融合成一个算子去操作完成,这样我们去自定义一个window partition的时候,内部就不需要感知view、permute等这样细致的逻辑。对于编译器来说,一条指令就可以完成window partition的操作。换句话说,像这种多个算子融合在一起的操作能不能用图优化或者编译器默认去做,而不在算法侧去做感知?理论上是可以的。
但图优化的另一个问题是需要维护大量pattern,也就是说只有在这样的优化规则下我才能得到最终的优化效果。我们大概看一下window partition的维度信息和多种格式的变化,这我可以衍生出一堆的写法。这种写法如果要在后面的编译阶段把所有的pattern都维护起来,对于自动的图优化来说还不如直接在算子层面使用一个固定格式、提供参数的方式让用户使用,而且这种替换几乎没有成本,也不需要重训。除了window partition和window reverse之外,还有一些常见的图优化,比如连续的Reshape和连续的Transpose的融合,这就可以直接用自动的图优化来做而不需要用户侧来感知。
另外一个重点是算子的实现优化,这看起来可能不是那么重要,但它对性能的提升是非常有效的。我们刚才讲,有一些历史遗留因素比如Reshape、Transpose之前在CNN模型中用的比较少,所以早期征程5上是使用DDR方式去实现算子的。为了性能的提升,把DDR的实现挪到SRAM的时候,可以发现整个Transformer部署有比较明显的性能提升,后面我们有详细的数据去说明。
另外一个特征是Batch MatMul的优化是普通循环做的tile优化。除此之外,还有一些其他比较琐碎的图优化,比如做elementwise算子或者concat/split算子。如果涉及到我前后需要用Reshape和Transpose得到一个具体维度的时候,而且只是GPU或者CPU上需要得到这个维度,但对于编译器或者对于征程5来说,这个维度信息可以穿透到需要计算的算子内部。比如我concat某一个维度,需要通过Reshape得到这个维度的话,其实Reshape的操作有可能只需要融合到concat,然后一次性做完就可以了。

另外,我们一直在说征程5对CNN模型是非常友好的,但是到Transformer模型上的话除了上面的图优化之外,还有一些比较明显的gap:征程5上以CNN为基础的模型仍然是最高效的模型,这一点表现在规则的4d-Tensor仍然是最高效的支持方式。为什么要讲规则的4d-Tensor呢?因为像CNN中的一些维度信息,比如W/H是做2倍下载样,C维度做4倍的扩充等,这些是非常有规则的。
所以在常见的嵌入式智能芯片平台上,我们会有一些基本的对齐操作,而征程5上做的是4d-Tensor的对齐。简单来说,我们支持三维的方式就是把一个非四维Tensor转成四维Tensor,我们也可以把一些不是特别重要的维度或者用来判定的维度使用一来做,然后4d-Tensor再结合嵌入式智能芯片常见的对齐操作。比如Conv的话我后面会讲,再比如征程5上channel维度基本上是8对齐,W维度是16对齐,如果这两个是非4d-Tensor转成4d-Tensor,结合对齐的情况来看,很可能在一些维度上做复杂对齐,这就会导致计算的效率极致降低,也会导致多了很多无用的计算。
所以我们基本上建议,如果可能性比较高的话可以使用一些4d的计算逻辑去替代任意维度上的操作,但这一点不是必须的,因为理论上目前在征程5上也是支持任意维度的操作的。如果想手动获取更高性能的话,可以使用目的性比较强的对齐4d-Tensor的规则去替换原来任意维度的计算。这里举个例子,比如我们可以用nn.Conv2d去替换nn.Linear,这个替换是等价的。比如我们把weight做一些Reshape操作,然后把2D、3D或者任意维度的东西去做一些维度融合或者维度扩充,经过Conv也是等价的,其他像BatchNorm、LayerNorm等是要结合Conv来看的。
最后是SwinT在征程5上优化的一个结论。通过上面一系列优化,可以把Swin-Transformer的量化损失降低到1%左右,同时部署的效率可以达到143FPS。我们可以看一下这里的优化选项,我们 Reshape和Transpose的优化非常明显,当然其他一些优化也是重要的,因为相对于FPS小于1的情况, Reshape和Transpose可能只是跨出了第一步而已。这里需要说明一下143这个数字可能跟之前在微信公众号发布的一些文档里的133有些区别,不过还是以143为主,因为经过我们在其他一些Transformer上面的探索发现这个数字在最近的最新版本上其实有一定的提升,相对来说可能比原来多了10FPS。然后我们也做了一个对比,这个数字跟端侧最强的GPU相比不会差太多。但另一方面,我们的功耗大概只有端侧最强GPU功耗的50%,这个数字还是非常可观的。
04
如何在征程5上既快又好地
部署Transformer模型
最后讲一下如何在征程5上既快又好地部署Transformer模型,并且把Swin-Transformer的经验推广到其它所有Transformer模型当中。
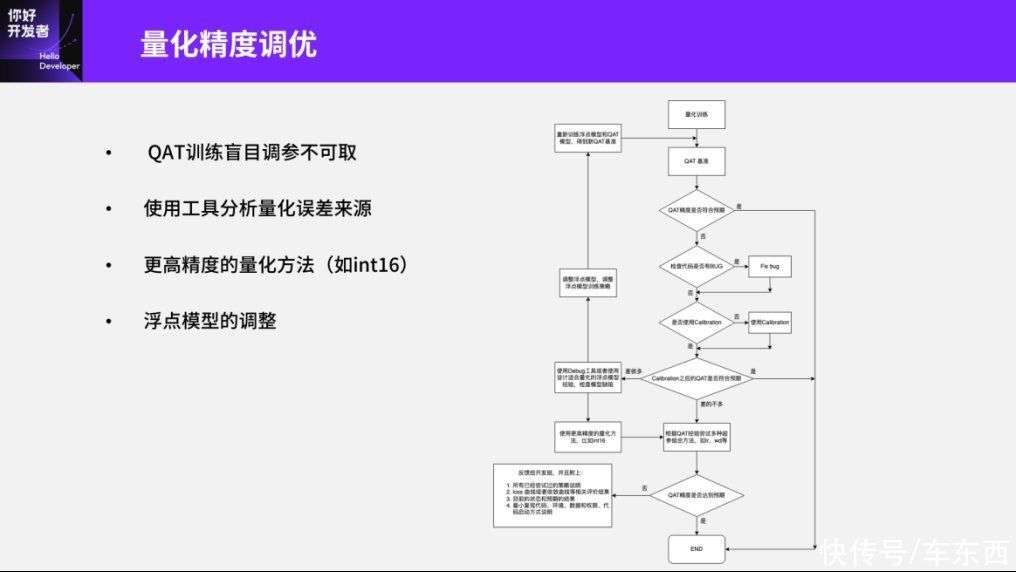
第一部分是量化精度的调优,其实刚刚已经讲到一些了,比如我们非常不建议盲目的使用PTQ方法,而建议使用一些量化工具、分析工具来分析误差本身的来源。另外,我们也非常不建议QAT本身的调参,因为对于工具本身的误差来源我们可以分析算子误差、模型误差、精度误差等这些方面。
我们后来发现,在Swin-Transformer模型当中一般的模型误差可能很难分析。这里可以举一个最简单的format的例子:比如我们在CNN模型当中,Conv+BN其实已经是一个标准的format了。Conv+BN的量化一般会在Conv前面和BN后面插入量化节点,这会导致如果Conv的输出范围比较大,那这个范围就不需要量化。因为整体上经过BN之后的Normalization就可以做量化了,这部分其实是不需要考虑的。但实际上这部分在Transformer里会出现一个很奇怪的现象,就是Linear的输出分布非常大,然后后面接的Normalization的方法是LayerNorm,而LayerNorm本身又不能和Linear一起去做量化。
所以这时候我们又会发现一个非常奇怪的现象,当我们用相似度分析模型误差时,会发现Linear前面的相似度误差可能不高,然而Linear后面的相似度误差急剧上升、误差很大,但是经过LayerNorm之后误差又降了下来。这种情况就需要分辨原来在CNN上面的结论,比如量化节点的误差或者模型的误差是否对Transformer非常有效?另外,我们更建议使用一些分布量化的方法去分析整个数据集或者精度上的误差,这样做可能更合理。遇到比较明显的量化误差,我们建议使用更高精度的量化方法。其实不仅是在征程5上使用int16更加方便,如果其他平台使用浮点或者FP16、BF16这样的浮点操作也是一个合理的解决方法。
最后讲一下,量化精度的前提是输入的浮点模型。我们发现量化模型相对于浮点模型来说,并不可以做到完全无损,这主要原因是当浮点模型中有一些非常大的weight或者输出的分布非常大甚至非常不均衡时,这本身对于量化来说就是非常不友好的。所以针对这些量化不友好的模型,我们建议对浮点模型做一定的调整,比如在分布不均衡的情况上加上一些Normalization,使它对输出的分布更加友好。
然后第二个是部署方面的建议,我们比较建议使用已经封装好的算子,比如像window reverse、window partition,还有matmul、LayerNorm等算子。可以通过天工开物芯片工具链里的QAT工具或者PTQ工具相应的接口去获取这些算子,如果有兴趣之后可以尝试使用一下。另外一个比较常用的算子天工开物工具链也是具备的,但是在Swin-Transformer中可能没有用到,就是MultiHeadAttention这个算子。目前,量化工具本身也是支持算子以及算子的部署优化的。
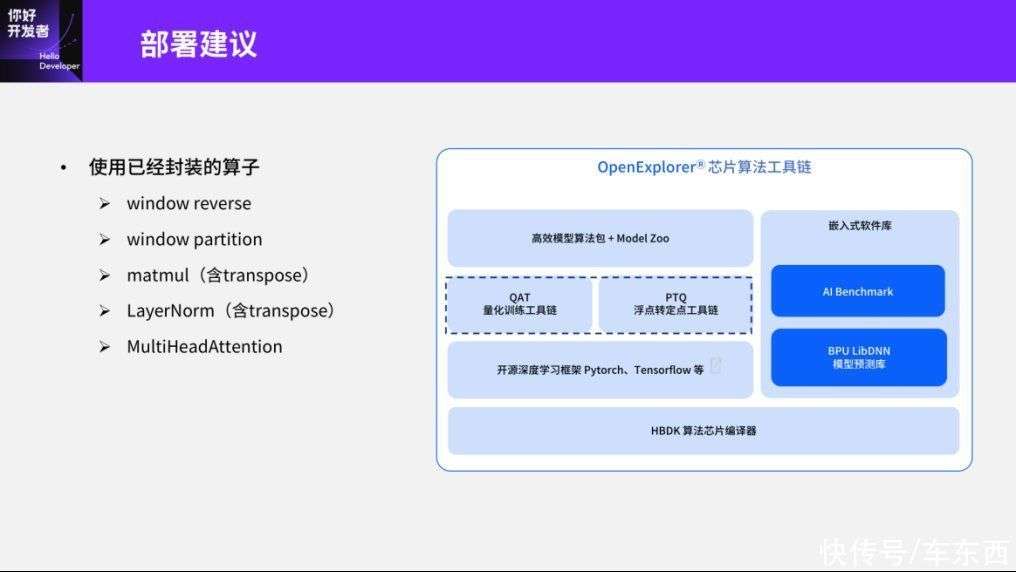
第三个是Tensor的对齐建议,其实我刚刚也在Swin-Transformer的部署优化中简单提到了,这里我们把征程5的基本情况列出来,包括Conv的一些基本运算部件、支持什么样的对齐策略。这个对齐策略如果想用细腻度优化去提升征程5的利用率的话,我们可以结合4d-tensor的优化思路,再结合pattern就可以进一步提高部署的利用率。Conv一般是H/W维度是26或者 channel维度是8对齐。如果对对齐策略有兴趣的话可以直接看。
另一个需要讲的是,除了算子在单个计算部件内部的对齐浪费开销之外,不同部件切换的时候也会有一些Reorder的算子开销。这个开销的原理比较简单:如果上一个计算部件的判定值比较小,比如说Conv在channel维度的判定值是8,当后面接的是一个ReduceSum算子时,channel维度的判定要求是256。所以当我们把一个Conv判定要求的算子以最小单位8塞到ReduceSum当中时,我们在很大范围里是做无效计算的。这个分析是一个比较特殊的例子,比较建议的方法是一个Conv接一个ReduceSum,这样正好在channel维度上有一个比较大的判定。
这样当Conv跟ReduceSum这两个组件切换的时候,就会有比较明显的Reorder的开销。有一个解决方法是我们用卷积来替代ReduceSum,这样的话计算方法也比较简单,其实跟我们之前做Conv替代linear这样的操作是类似的。比如我用reduce在C维度上去做ReduceSum的话,它的kernel大小就可以用(C,1,1,1)来表示,这样我在C维度就从原来的C变成1,而Reduce on H就是(C,C,H,1)。

最后分享一下未来的一些工作。在征程5上部署SwinT其实是我们去年的工作,随着工具链参考模型的发布,我们会有更多Transformer模型发布,比如说像DETR,DETR3d,PETR等,同时我们也会有更多Transformer相关的算子,比如量化Debug工具,还有一些经验等也会沉淀到工具链当中。另外,征程5上的一些生产模型也会探索更多Transformer模型的可能性。
其实像Swin-Transformer更多是做了一个验证的过程——验证征程5的可行性,但实际在生产模型上,如果FPS要求极高的话,我们更建议的做法是在一些CNN操作中内嵌一些Transformer操作,比如我们可以参考现在比较流行的MobileNet、ViT的优化,或者在BEV、时序上采用Transformer的方法做一些特征融合,而不使用以前那些卷积的方法。这样少部分使用Transformer不仅能提高模型性能,而且在征程5上的部署效率也会更高。最后推广到其他非CV任务上,事实上我们已经在做语音方面的Transformer在征程5上的部署。
总体上我的分享就这么多,如果大家有兴趣的话,可以去访问地平线的开发者社区(https://developer.horizon.ai/),里面会有更多工具链的细节,开放的相关文档与参考算法,大家如果有什么问题的话也可以在里面交流。
","gnid":"91ab8548302f319b7","img_data":[{"flag":2,"img":[{"desc":"","height":"350","title":"","url":"http://p0.img.360kuai.com/dmfd/__60/t01f0fd258fb85f9309.jpg","width":"800"},{"desc":"","height":"572","title":"","url":"http://p0.img.360kuai.com/dmfd/__60/t013eca971e7ac9e673.jpg","width":"1016"},{"desc":"","height":"572","title":"","url":"http://p2.img.360kuai.com/dmfd/__60/t010ccd8ffe03bac0a2.jpg","width":"1016"},{"desc":"","height":"608","title":"","url":"http://p0.img.360kuai.com/dmfd/__60/t0155e1a51bc910821a.jpg","width":"1080"},{"desc":"","height":"572","title":"","url":"http://p1.img.360kuai.com/dmfd/__60/t01b59c1a257b1f65e7.jpg","width":"1016"},{"desc":"","height":"572","title":"","url":"http://p1.img.360kuai.com/dmfd/__60/t015ca2285dd24a87c2.jpg","width":"1016"},{"desc":"","height":"572","title":"","url":"http://p0.img.360kuai.com/dmfd/__60/t01982ef0ca562c8988.jpg","width":"1016"},{"desc":"","height":"572","title":"","url":"http://p0.img.360kuai.com/dmfd/__60/t013cb49af13f7bfee9.jpg","width":"1017"},{"desc":"","height":"572","title":"","url":"http://p1.img.360kuai.com/dmfd/__60/t01700b4b408d6eb0b8.jpg","width":"1016"},{"desc":"","height":"572","title":"","url":"http://p0.img.360kuai.com/dmfd/__60/t01945d51b6551d8f2c.jpg","width":"1016"},{"desc":"","height":"572","title":"","url":"http://p0.img.360kuai.com/dmfd/__60/t015fcbd6083c6986b6.jpg","width":"1016"},{"desc":"","height":"572","title":"","url":"http://p1.img.360kuai.com/dmfd/__60/t01d20aeef357d1ff2a.jpg","width":"1016"},{"desc":"","height":"572","title":"","url":"http://p2.img.360kuai.com/dmfd/__60/t0157a712698eacad66.jpg","width":"1016"},{"desc":"","height":"572","title":"","url":"http://p2.img.360kuai.com/dmfd/__60/t011c4cf6336c92a7e1.jpg","width":"1016"},{"desc":"","height":"572","title":"","url":"http://p2.img.360kuai.com/dmfd/__60/t01221c591982b798c7.jpg","width":"1016"},{"desc":"","height":"572","title":"","url":"http://p0.img.360kuai.com/dmfd/__60/t011b7056d2a085fc28.jpg","width":"1016"},{"desc":"","height":"572","title":"","url":"http://p1.img.360kuai.com/dmfd/__60/t01fe33d8aa0828ec0e.jpg","width":"1016"}]}],"original":0,"pat":"art_src_3,fts0,sts0","powerby":"hbase","pub_time":1681269780000,"pure":"","rawurl":"http://zm.news.so.com/32c0af388b1dc52005b7ed9723f4d176","redirect":0,"rptid":"a3e710b9e232693b","rss_ext":[],"s":"t","src":"车东西","tag":[{"clk":"ktechnology_1:芯片","k":"芯片","u":""},{"clk":"ktechnology_1:杨志刚","k":"杨志刚","u":""}],"title":"地平线杨志刚:基于征程5芯片的Transformer量化部署实践与经验